Introduction
Businesses request automation. They receive one chatbot that’s guessing, hallucinating, or constantly being babysat by a human. That’s not automation. That’s a prototype.
We build multi-agent systems with OpenAI’s Agents SDK that solve real business problems: pulling verified data, running domain logic, making decisions, and taking actions — all with clear audit trails and human-in-the-loop controls. The result is repeatable, testable automation that reduces manual effort and preserves compliance.
Here’s the approach that turns experiments into production and prospects into clients.
The short problem statement (what’s broken now)
You have workflows that require:
- Drawing from multiple systems
- Enforcing domain rules
- Composing communications that need to be auditable
- Calling out to external systems safely.
One LLM attempting to do everything falls apart. It hallucinates, it blurs responsibility, and introduces risk at scale. The right alternative is to divide responsibility into targeted agents, coordinate them, and execute them with observability and control.
What the Agents SDK provides in simple language
The SDK is an environment for constructing small, specialist agents and connecting them up. Practical advantages:
- Concise agent roles, so it’s easy to debug,
- Explicit tool integration (databases, search, APIs), so agents don’t guess,
- Handoff primitives, so one agent completes before the next one begins, and
- Tracing and logs, so you can explain decisions afterwards.
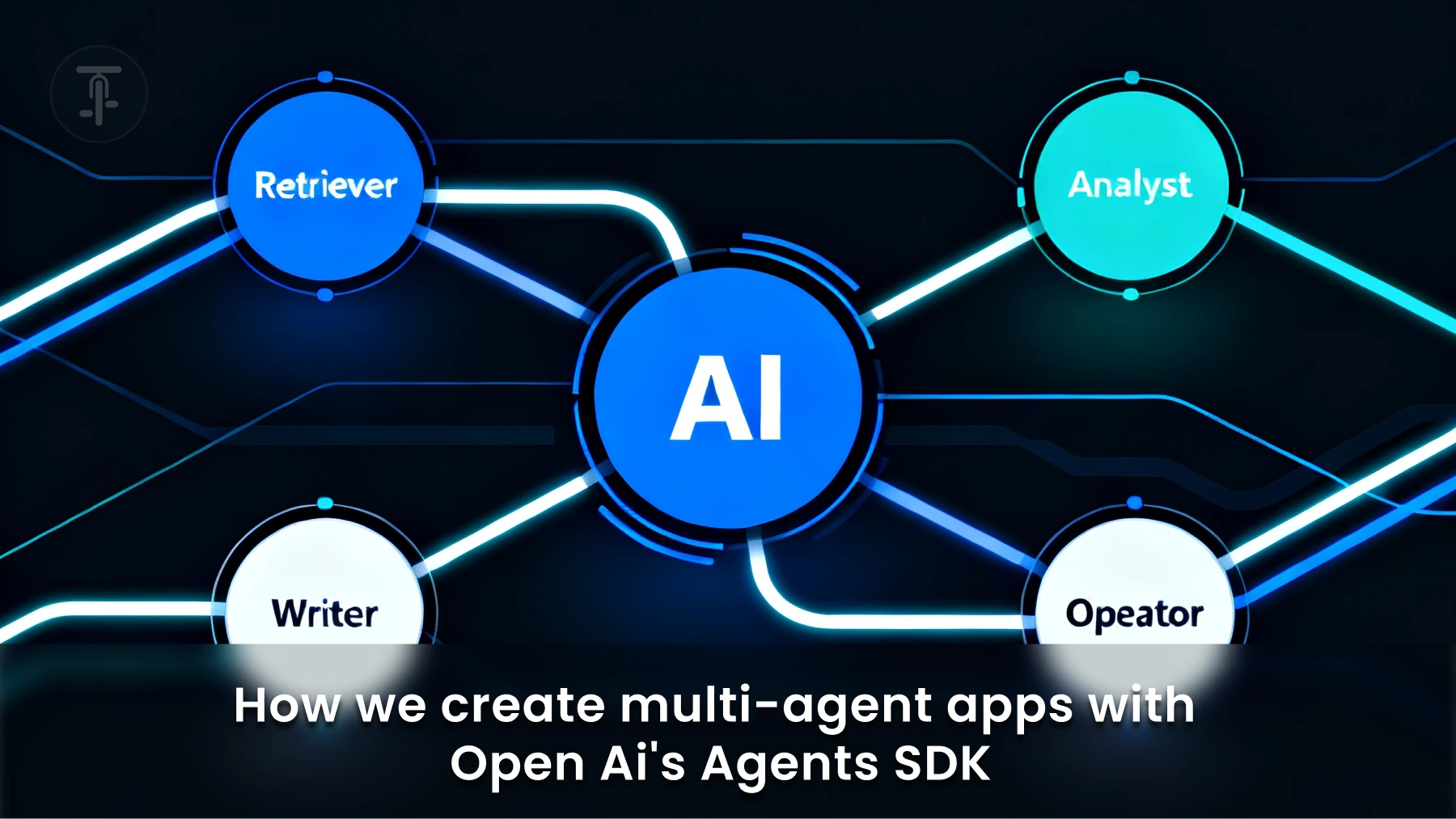
We enclose those primitives in a production pattern: intake, retriever, analyst, writer, operator, orchestrator, and safety layer.
Client Achievements Drive Our Value
When you collaborate with Pedals Up on an agency project, you receive outcomes, not demos:
- Quicker resolution. Agents perform redundant retrieval and triage; humans examine only exceptions.
- Auditability. Each decision specifies which data and tool created it. That minimizes compliance risk.
- Previsible costs. We architect agent budgets and caps so you don’t get bills out of the blue.
- Shrunk time-to-value. We ship a pilot in weeks, not months.
- Clear handoffs. Agents either complete a task or escalate, never both.
All of these lines correspond to quantifiable KPIs we define during discovery: time-to-resolution, percent automated, false-positive rate, and cost per transaction.
Production blueprint for agent architecture
We employ a simple, repeatable architecture that prospects can see at a glance.
Intake agent (router)
- Purpose: classify the request and develop a short execution plan.
- Output: explicit workflow and chosen specialist agents.
Retriever agent
- Purpose: retrieve authenticated records, logs, and documents.
- Rule: never make things up. All retrievals give back source IDs.
Analyst/Heuristic agent
- Purpose: apply domain rules and business logic to retrieved data.
- Output: formatted decision and confidence level.
Writer agent
- Purpose: create user-readable messages that cite sources and rules employed.
- Output: templated drafts ready for review or dispatch.
Operator agent
- Purpose: invoke external APIs (ticketing, payments). Always executes with an action threshold and an audit checkpoint.
Orchestrator and Guardrails
- Purpose: route handoffs, reattempt failed tool calls, apply cost limits, and route to human audit when not confident.
Observability layer
- Purpose: record traces, tool calls, latency, and costs. They feed dashboards and tests.
We provide diagrams and the agent specifications, not fuzzy architecture slides.
How we select models and manage cost
We don’t fall into the single-model fallacy. Our rules:
- Employ light models for routing and retrieval to keep latency low
- Reserve stronger models for only complex reasoning or final production
- Maintain a cost limit per request enforced by the orchestrator
- Batch calls to tools whenever possible to cut down on round-trip.
We set prior budgets for models for each agent and run 100 synthetic test runs to estimate monthly expenditure before signing a build contract.
How do we make systems honest

If you can’t reproduce a decision, you can’t correct it. So we instrument:
- Agent-level unit tests (simulate tool responses),
- End-to-end smoke tests with flaky tool scenarios,
- Trace capture on all runs: inputs, outputs, tool arguments, and response times, and
- Monthly rebaseline against production traces.
This allows us to find drift, test guardrails, and make agents better incrementally.
Common failure modes and how we avoid them
Agents may fail predictably. Here’s how we prevent each failure:
- Divergent agent goals — we lock the execution plan and insist on validation after each handoff.
- Synthetic tool outcomes — each retrieval has a source ID and schema checking.
- Overages — the orchestrator imposes per-request limits and monthly quotas.
- Drift — production traces go into monthly rebaselining.
And: human-in-loop for high-risk decisions, and an incident playbook for surprise failures.
Pilot plan we actually employ
Week 1 — Discovery and measures of success
- Map out workflow, select sample data, and determine KPIs.
Week 2 — Agent design and spec
- Author agent instructions, specify tools, and safety limits.
Weeks 3–4 — Pilot build
- Attach tools to the retriever, deploy orchestrator and tracing, and execute synthetic tests.
Week 5 — Pilot run
- Execute with human reviewers, collect traces, and quantify KPIs.
Week 6 — Pilot report and next steps
- Provide a performance report, cost estimate, and production plan.
This plan is contained within an expected fixed-price engagement and provides you with a definitive point of decision following the pilot.
FAQs your procurement or security team will pose
- Will agents process sensitive information? Yes. Agents only access sensitive information via the scoped tools we create and inspect. We can deploy under your cloud account.
- How do you avoid hallucinations? We never allow an agent to make up a record. Retrievals provide source IDs and schema validation. Approved sources are all the writer agent can use.
- How do you manage costs? Per-agent limits and orchestrator-level limits. We also model the cost during the pilot.
- How quickly to production? Pilot within 4–6 weeks, production in 3–6 months based on integrations.
Why Pedals Up
We deliver agentic systems that ship: engineering-quality, observable, and governed — and we make pilots affordable and quick so you can see impact before you invest.
Schedule a 30-minute discovery call. We’ll review one workflow, illustrate a suggested agent split, and provide a flat-rate pilot plan you can show stakeholders. No vague proposals. No hidden expenses. Schedule here: https://pedalsup.com/our-services


